


北航高性能计算平台使用常见问题解答
1.0 版本
北京航空航天大学信息办高算中心
2020年12月
一、 用户登录与连接相关
暂时VPN不能直接链接高算,需要申请堡垒机,申请步骤请联系高算服务群里管理员
Q1: VPN无法连接,或者连接超时。
A:下载并重新安装easy connect下载地址:https://vpn.buaa.edu.cn/portal/#!/login,输入正确VPN地址:https://vpn.buaa.edu.cn
注:北航校内网环境下无需使用VPN,可直连HPC平台。
Q2: VPN账户密码遗忘。
A:登录VPN使用的是统一认证账号密码,找回密码请登录ucs.buaa.edu.cn,选择通过手机找回,输入学号/教工号即可。
Q3: HPC平台账户密码遗忘。
A:用户交流群中联系平台管理员协助进行密码重置,或者发送问题说明邮件至hpc@buaa.edu.cn。
Q4: SSH连接到平台,长时间不操作,会话自动断开。
A:不同的ssh工具都有默认会话保持设置,请检查此项设置,若是频繁自动断开,请检查本地网络环境。
Q5: 在登录节点编译运行时出现终端自动断开现象。
A:编译会占用登录节点CPU资源,若超过系统设定阈值,即:进程CPU使用率>=100%,且运行时间超过15分钟、进程内存使用大小超过10GB,则会被系统监控查杀进程。cp、scp、tar传输解压命令占用超过阈值除外,建议将编译过程写成调度脚本,通过调度作业编译。
Q6: SSH登录平台,输入错误的用户名密码后再输入正确的用户名密码却提示密码错误,拒绝连接。
1) A:短时间内登录输错3次密码,那么登录时所使用IP将被自动封锁5分钟。可尝试换登录节点(10.212.66.4、10.212.66.5、10.212.70.128)登录,3个节点数据共享,锁定机制独立,或者等待5分钟再认证。
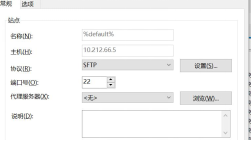
Q7: 使用终端如xftp无法从平台下载文件。
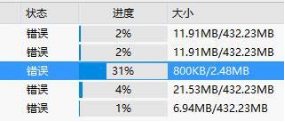
A:建议使用xshell终端,使用sz 文件名下载,若使用XFTP,则检查如下参数。
Q8: 原来都是在windows上操作软件,不会用Linux,我现在想学习一些基本的Linux操作,满足超算上机需要,应该学哪些内容?
A:首先了解一下Linux的目录结构,Linux的目录以树形组织。
其次学习几个常用的Linux命令,主要是:
pwd –查看当前所在目录
cd –改变目录
cp –复制文件
rm -删除文件
mv –文件重命名
mkdir –创建目录
然后学习作业管理相关的命令:
sbatch –提交作业
scancel job–取消作业
scontrol show job –查看作业状态
sinfo -查看节点信息
有关slurm的具体使用请参考“北航校级计算平台-用户手册(正式版V1.0).pdf”或相关网络资料。
A.在校内使用校园网链接不上高算平台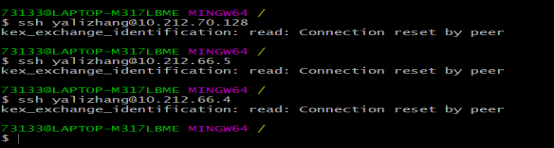
出现这类报错是因为平台内有输入错误密码超过十次就会锁本地ip,需要高算管理员解锁ip才能正常登录
A.在校外暂时不能使用校内vpn链接,后续还会回复,等校内老师在群里通知,在校外要连接高算平台可以申请高算堡垒机进行远程链接
https://bhblj.buaa.edu.cn
Q9: 是否可以提供root或者sudo权限,用来进行软件或者环境包安装
A:root或者sudo权限,任何情况下,都不会提供给用户。
如果是需要执行yum install这样的操作,平台大部分依赖包已基本安装好,如果缺少相关的软件包,请把软件包名字告诉超算管理员,让管理员来安装。
如果是执行apt install,需要注意北航HPC平台为centos 7系统,不是Debian/Ubuntu系统,需要安装的包可能在centos叫其他的名字,如果你后续的安装使用步骤提示确实缺少依赖包,请把这个依赖包的名字告知超算管理员,让管理员来安装。
Q10: 如何在主机上安装软件?
A:(a)如果有开源源码包,可以直接在自己家目录编译安装;
(b)使用anaconda环境安装,比如安装opencv、pytorch、TensorFlow;
(c)如果有正版软件许可,可以联系管理进行安装,例如:Comsol、ABAQUS;
注意:平台不建议用户安装破解或者盗版软件,用户须自行负责相关软件的版权问题。
Q11: 我想在主机上自行编译软件,需注意哪些问题?
A:(a)首先确定您的软件的系统要求、编译器版本要求、依赖的软件包,主机上已预装了一部分工具软件,例如查看系统预装依赖包: rpm -qa | grep 包名称
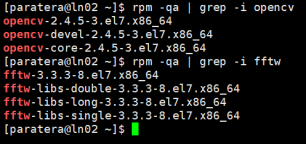
(b)设置好编译环境,准备好软件包来进行编译测试;
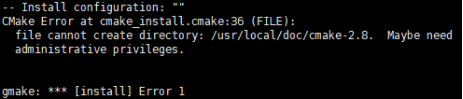
如上图所示,一般编译安装软件没有修改默认的安装路径(通常是 /opt /usr/local 这样需要 root 权限的系统目录)。要解决这类问题,如果是从源代码编译软件,一般是在 configure 的时候使用 --prefix= 这个选项把安装目录指定到用户自己的目录下。如果是安装型的软件,在安装向导里修改默认的安装目录为用户自己的家目录。
注意:如果是大型软件,编译测试可能需要占用大量CPU的,请使用调度系统编译测试。
(c)如果安装包是ISO格式文件,请在本地解压ISO文件内容,并打包成zip格式压缩包再上传至平台安装。因为ISO文件只有root权限可以使用mount命令挂载。
Q12: 发现主机的编译器版本很低,无法满足我的需要,怎么办?
A:主机出于系统稳定性、可用性的需要,编译器和库文件的更新周期较长,因此建议您:
(a)联系我方技术服务人员,或者自行在目录下安装编译器和其他工具软件,注意需在.bashrc里设置相应的路径;
(b)一些系统底层的api如glibc的版本无法进行更新。
Q13: 作业执行时提示,程序无执行权限问题。如图

A:建议使用chmod命令给执行文件加执行权限,chmod +x即可。
Q14: 如何使用mpif9、mpicc、mpirun等命令?
A:使用module load intel命令加载,示例如下:

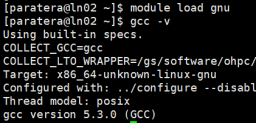
Q15: 如何查看gcc 的路径以及相关信息?
A:查看gcc5使用如下命令:
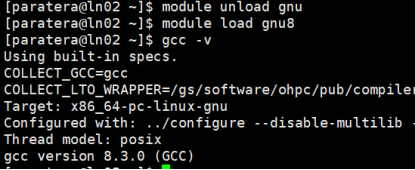
查看gcc8使用如下命令:
注意,需要先module unload gnu,避免冲突。
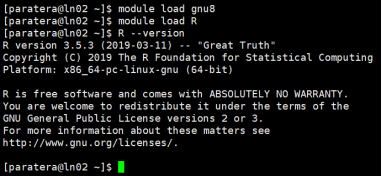
Q16: 如何使用R,R语言依赖于gnu8,所以需要先加载gnu8,如直接使用module load R,会提示找不到模块。
A:使用如下命令:
Q17: 如何使用openmpi,Openmpi依赖于intel的mpi模块,所以需要先module load intel 。
A:使用如下命令:

Q18: 如何删除乱码文件?
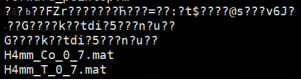
A:首先使用ls命令定位具体文件:ls -i查找文件i节点名,然后再使用find命令进行删除:find -inum 节点号 -delete删除节点号文件。如图:

Q19: Q:如何使用anaconda安装软件
A:可以根据用户手册,module与anaconda章节,自定义环境配置与软件安装部分,例如安装Pytorch,自定义配置安装conda环境,并使用pip install python=3.6 pip install pytorch即可安装相应软件。
Q20: 在自定义conda环境安装了某软件,提交作业后提示找不到软件模块,比如:
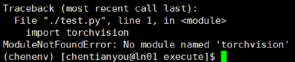
A:conda activate 自定义环境,并使用conda list | grep 软件名,查看当前conda环境是否有此软件;若有,再执行import 软件名,看是否有报错,并确定软件python版本是否匹配,若正常则修改脚本,脚本中可以添加以下命令:
module load anaconda3 source activate testenv(比如:TensorFlow安装在了testenv环境中) |
并退出到base环境(anaconda)提交作业,conda deactivate即可退出。
Q21: 用户之间如何进行数据共享?
A:平台中的目录/gs/sharedata/用户名,即为用户共享目录,不同用户可进行数据共享,共享完数据,请随即删除数据,释放存储空间。
注:共享空间也受单用户2T磁盘配额限制。
Q22: mac和Linux操作系统与高算平台如何传输文件?
A:无需下载传输工具,使用MAC或LINUX系统自带的scp命令即可实现。
1)上传单个文件:
scp /users/test/Desktop/helloworld.c test@10.212.66.5:/gs/home/test
2)下载单个文件:
scp test@10.212.66.5:/gs/home/test/helloworld.c /users/test/Desktop
3)上传单个文件夹:
scp -r /users/test/Desktop/test test@10.212.66.5:/gs/home/test
4)下载单个文件夹
scp -r test@10.212.66.5:/gs/home/test/test /users/test/Desktop
Q.图形化界面的操作平台用不了,后续还会开放吗?
A:目前由于安全原因禁用,暂时没有解禁的打算
Q.为什么pip 安装wheel包仍需要联网
A: 需要检查依赖,添加上 --no-deps
Q23: 提交脚本报错如下,DOS line、UNIX line等。

A:此问题多为Windows平台编写命令直接上传到平台导致,使用dos2unix命令转换脚本,建议使用vim命令编写脚本。
Q24: 提交的作业没有实时输出信息。
A:可以尝试在print函数里面加上 ",flush=True"参数,让打印信息的时候刷新标准输出。
Q25: 作业提交后无法使用nvcc、nvidia-smi等需要调用GPU程序的命令,或者找不到libcuda.so文件。
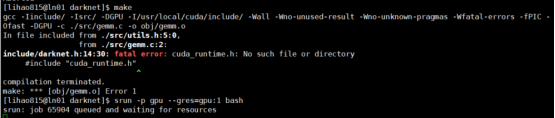
A:检查脚本是否提交到了GPU分区、是否有添加 #SBATCH –-gres=gpu:1 参数。如果使用的是srun模式,需要先申请GPU卡资源,再进行程序交互测试。
Q26: 申请到gpu卡,输入nvcc -V提示找不到命令。
A:使用命令module load cuda/10.1加载模块,或者个人环境变量.bashrc中加入:
export PATH=/usr/local/cuda/bin:$PATH
Q27: 提交作业已成功运行,但是运行结果提示killed。
A:此类问题多为计算程序在节点使用了过多的内存,被系统杀死。建议修改计算程序的模块尺寸等与内存相关的参数,或者脚本中添加--mem=<size[units]>参数,具体使用可参考sbatch命令man手册:man sbatch | grep -i mem
Q28: 提交的作业占用内存较大,会挤掉其他用户的作业,报错:out of memory
A:通常这种情况多数出现在gpu节点,计算如TensorFlow的程序,此类情况建议用户可以降低程序的网络复杂度,或者降低batch size;如果是图片的话可以将resize调整小一些。
Q29: 任务或者作业已经成功提交,显示在排队,如何知道需要排队多久。

A:等待时间根据平台当前资源而定,具体可以使用命令scontrol show job jobid查看如下信息。

此外,单用户最大同时可运行3个作业,超过3个的作业,提交任务成功,也会显示排队PD状态或者QOSMaxJobsPerUserLimit。
Q30: 提交的任务已经排队很久了,依旧没有正常运行。

A:使用squeue -u 用户名查看作业目前状态,根据状态定位为PartitionTimeLimit,即为超过分区时间最大3天的限制。此类作业会一直排队,无法执行,请遵循平台用户作业限制规范重新提交。
Q31: srun和sbatch提交任务有什么区别
A:srun是调试模式,是交互模式操作,用户程序调试,如果网络问题,或者人为断开终端,则申请资源即刻释放。
sbatch类似后台命令提交,作业提交成功后,若程序没问题,申请资源不受终端断开,或者网络原因而中断。
Q32: 提交的作业报错信息为超时,如果修改执行时间,任务是否会继续执行。
A:任务会终止,资源随即释放,需要重新提交,建议任务时间不超过系统规定的7天时间。
Q33: 如何在系统中对程序进行调试?
A:对程序的调试可以通过作业调度系统分配到计算节点上。srun和salloc都可以用于交互式调试应用,当调试的计算量比较大时,请不要在登录节点上直接运行,高负载的用户进程会被系统守护进程杀掉。
具体操作如下(以分配GPU卡为例):
1)执行:srun -n 1 -p gpu –gres=gpu:1 /bin/bash
接着执行:nvidia-smi
可以看到系统分配了一块GPU卡。中断交互调试,任务结束。
2)执行:sbatch -n 1 -p gpu –gres=gpu:1 /bin/bash
接着执行:srun nvidia-smi
可以看到系统分配了一块GPU卡。
退出终端,任务结束。
Q34: 如何获得作业运行时环境变量?
A:Slurm作业调度系统运行时输出的主要环境变量如下:
SLURM_ARRAY_TASK_ID:作业组ID(索引)号;
SLURM_ARRAY_TASK_MAX:作业组最大ID号;
SLURM_ARRAY_TASK_MIN:作业组最小ID号;
SLURM_ARRAY_TASK_STEP:作业组索引步进间隔;
SLURM_ARRAY_JOB_ID:作业组主作业号;
SLURM_CLUSTER_NAME:集群名;
SLURM_CPUS_ON_NODE:分配的节点上的CPU数量;
SLURM_CPUS_PER_TASK:每个任务的CPU数量;
SLURM_JOB_ID 作业号;
SLURM_JOB_CPUS_PER_NODE 每个节点上的CPU颗数;
SLURM_JOB_DEPENDENCY:作业依赖信息,由–dependency选项设置;
SLURM_JOB_NAME:作业名;
SLURM_JOB_NODELIST:分配的节点名列表;
SLURM_JOB_NUM_NODES:分配的节点总数;
SLURM_JOB_PARTITION:使用的队列名;
SLURM_JOB_RESERVATION:作业预留;
SLURM_LOCALID:节点本地任务号;
SLURM_MEM_PER_CPU:类似–mempercpu,每颗CPU的内存
SLURM_MEM_PER_NODE:类似–mem,每个节点的内存;
SLURM_NODE_ALIASES:分配的节点名、通信IP地址和主机名组合;
SLURM_NODEID:分配的节点号;
SLURM_NTASKS:类似-n,–ntasks,总任务数,CPU核数;
SLURM_NTASKS_PER_CORE:每个CPU核分配的任务数;
SLURM_NTASKS_PER_NODE:每个节点上的任务数;
SLURM_NTASKS_PER_SOCKET:每颗CPU上的任务数,仅–ntaskspersocket选项设定时设定;
SLURM_PRIO_PROCESS:进程的调度优先级(nice值);SLURM_PROCID:当前进程的MPI秩;
SLURM_PROFILE:类似–profile;
SLURM_RESTART_COUNT:因为系统失效等导致的重启次数;
SLURM_SUBMIT_DIR:sbatch启动目录,即提交作业时目录;
SLURM_SUBMIT_HOST:sbatch启动的节点名,即提交作业时节点;
SLURM_TASKS_PER_NODE:每节点上的任务数;
SLURM_TASK_PID:任务的进程号PID;SLURMD_NODENAME:执行作业脚本的节点名。
Q35: 作业执行不正常时如何查看原因
A:用户提交作业后,是否运行取决于用户申请的资源情况和当前系统的情况。建议使用squeue命令来查看所有已经提交和正在运行的作业。其中 NODELIST(REASON) 一栏包含非常有用的信息,在作业未运行时,它会显示未运行的原因;当作业在运行时,它会显示作业是在哪个节点运行的。
下面是作业未正常运行的原因:
原因代码 |
详细说明 |
BeginTime |
未到用户所指定的任务开始时间 |
Dependency |
该作业所依赖的作业尚未完成 |
InvalidAccount |
用户的 SLURM 账号无效 |
InvalidQOS |
用户指定的 QoS 无效 |
ParitionTimeLimit |
用户申请的时间超过该分区时间上限 |
QOSMaxCpuPerUserLimit |
超过当前 QoS 用户最大 CPU 限制 |
QOSMaxGRESPerUser |
超过当前 QoS 用户最大 GRES(GPU) 限制 |
Priority |
存在一个或多个更高优先级的任务,该任务需要等待 |
ReqNodeNotAvail |
所申请的部分节点不可用 |
Resources |
暂无闲置资源,该任务需等待其他任务完成 |
Q36: 修改已经提交作业的cpu节点个数应该使用什么命令
A:可以使用如下命令:
scontrol update jobid=** NumCPUs=*** NumNodes=***
其他scontrol相关的命令参数,可以使用man scontrol查看。
Q37: 如何一次提交多个小作业?
A:可能有的用户在考虑如何一次提交多个小作业,又不会被系统3个同时运行作业的规定限制。可以尝试下面的脚本,注意最后那个wait不能丢。
#!/bin/bash
#SBATCH -J test # 作业名是 test
#SBATCH -p normal # 提交到 normal分区
#SBATCH -n 4 # 提交4个task
#SBATCH --cpus-per-task=1 # 每个task占用一个 cpu 核心
#SBATCH -t 5:00 # 任务最大运行时间是 5 分钟
#SBATCH -o test.out # 将屏幕的输出结果保存到当前文件夹的 test.out
srun -n 1 /usr/bin/sleep 100 &
srun -n 1 /usr/bin/sleep 100 &
srun -n 1 /usr/bin/sleep 100 &
srun -n 1 /usr/bin/sleep 100 &
wait
在GPU分区如何提交多个小作业?
可以尝试下面的脚本:
#!/bin/bash
#SBATCH -J testsleep # 作业名是 test
#SBATCH -p gpu-normal # 提交到 normal分区
#SBATCH -n 4 # 提交4个task
#SBATCH --cpus-per-task=1 # 每个task占用一个 cpu 核心
#SBATCH -t 5:00 # 任务最大运行时间是 5 分钟
#SBATCH -o test.out # 将屏幕的输出结果保存到当前文件夹的 test.out
#SBATCH --gres=gpu:3
srun -n 1 --gres=gpu:1 python3 main1.py &
srun -n 1 --gres=gpu:1 python3 main2.py &
srun -n 1 --gres=gpu:1 python3 main3.py &
wait
修改已经提交作业的cpu节点个数应该使用什么命令
可以使用如下命令:
scontrol update jobid=** NumCPUs=*** NumNodes=***
其他scontrol相关的命令参数,可以使用man scontrol查看。
提交作业的时候系统显示所需分区不可用

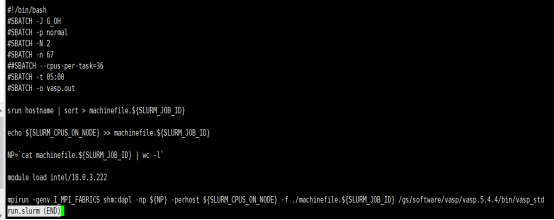
A: 没有所提交的normal队列了
提交作业时显示,计时已结束,请联系管理员
A:导师账号余额不足,不能使用作业系统
OpenMP和MPI混编,多节点运行,sbatch脚本文件应该怎么写
A: mpirun -genv I_MPI_FABRICS shm:dapl
shm:dapl就是OpenMP和MPI混合的选项
优先以sharememory方式运行
OpenMP和MPI的具体编程的方法,可以参考Intel编译器的手册,里面有具体的函数调用方法说明。
A.提交到某个节点出现一下报错![]()
exclude掉特定节点提交可以解决
A.简单节约研究经费方法
cpu-high改为cpu-low节约一半研究经费,不影响速度,多节点是否会加速,还得看你的multiprocessing写的是否兼容
cpu-high改为cpu-low的区别在于在资源紧张情况下high减少排队时间
A. 能够打印运行结果的运行程序的方法
cpu high bash:在print函数里面加上 ",flush=True"参数,让打印信息的时候刷新标准输出
应用计算相关
Q38: 使用ansys提交作业后,报错:Licensed number of users already reached。
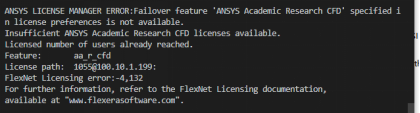
A:此报错为用户使用达到许可数量限制,需等待空闲许可。
Q39: 提交ansys作业报错:Not enough Fluent
![]()
A:此报错为提交的作业并行核数超过了目前可用并行数。
Q40: 使用pycharm计算任务,无法显示图形化报表。
A:在程序中加入以下代码:
import matplotlib matplotlib.use('Agg') |
上述代码一定要添加在import matplolib.pyplot之前,否则无效。
Q41: lammps编译的时候,出现make[1]: mpicxx: Command not found
A:mpicc没有环境变量,需要使用命令module load intel加载intel模块。
Q42: 使用pytorch时,程序挂载在gpu节点上,但是没有用到显卡,并报错:cuda_is_available false
A:检查脚本,是否有添加--gres参数,脚本没有此参数,则默认不分配GPU卡。建议添加显卡申请参数,--gres最大不超过2,即单用户最大2块显卡。
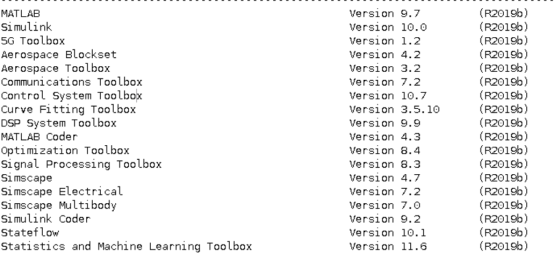
Q43: 平台MATLAB软件有哪些已经安装的工具箱?
A:平台MATLAB已经安装工具箱如图
Q44: 计算报segmentation fault错误。
A:segmentation fault是由于程序代码访问内存异常造成,常见于C/C++程序代码中使用指针或数组访存操作。有些是访问了已经释放的内存,有些是访问了未经申请的内存,有些是数组越界访问,有些是使用的库版本不兼容,等等,原因各不相同。
一般的解决方法是,如果有源代码,则使用调试工具进行单步跟踪调试,逐步定位访存异常的代码,并逐步回溯,直到找到出现错误的原因。如果没有源代码,则需要使用内核转储的分析工具对转储文件进行分析,分析工具的具体使用方法可到网上查找。
Q45: 如何在系统中使用Infiniband网络
A:本系统配置了Infiniband网络,在使用IntelMPI和OpenMPI时,可以通过指定参数使用Infiniband网络。
1)使用IntelMPI时,请在运行mpirun时增加如下选项:
--genv I_MPI_FABRICS shm:dapl
2)使用OpenMPI时,请在运行mpirun时增加如下选项:
--mca btl self,sm,openib
Q46:超算上fluent标准算例无法运行
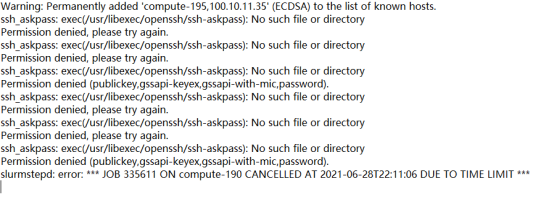
A:你ssh的key被删掉了,需要重新帮你生成了

A: X11图形界面转发,srun 添加 --x11的参数
Q:例子 转发xterm:srun -p cpu-low --x11 xterm
参考连接:
https://slurm.schedmd.com/faq.html#x11
https://portal.supercomputing.wales/index.php/index/slurm/interactive-use-job-arrays/x11-gui-forwarding/
A:请问cpu36核全用,一次最多能申请多少个啊?
Q:有一个理论的最大值,cpu-x分区就有260个节点;cpu68只有68个节点,建议就是10个节点并行,不要太多
